Fast learning rate calibration for the Gibbs posterior
tuneLearnFast.RdThe learning rate (sigma) of the Gibbs posterior is tuned either by calibrating the credible intervals for the fitted curve, or by minimizing the pinball loss on out-of-sample data. This is done by bootrapping or by k-fold cross-validation. Here the loss function is minimized, for each quantile, using a Brent search.
tuneLearnFast(form, data, qu, err = NULL, multicore = !is.null(cluster), cluster = NULL, ncores = detectCores() - 1, paropts = list(), control = list(), argGam = NULL)
Arguments
| form | A GAM formula, or a list of formulae. See ?mgcv::gam details. |
|---|---|
| data | A data frame or list containing the model response variable and covariates required by the formula. By default the variables are taken from environment(formula): typically the environment from which gam is called. |
| qu | The quantile of interest. Should be in (0, 1). |
| err | An upper bound on the error of the estimated quantile curve. Should be in (0, 1).
Since qgam v1.3 it is selected automatically, using the methods of Fasiolo et al. (2017).
The old default was |
| multicore | If TRUE the calibration will happen in parallel. |
| cluster | An object of class |
| ncores | Number of cores used. Relevant if |
| paropts | a list of additional options passed into the foreach function when parallel computation is enabled. This is important if (for example) your code relies on external data or packages: use the .export and .packages arguments to supply them so that all cluster nodes have the correct environment set up for computing. |
| control | A list of control parameters for
|
| argGam | A list of parameters to be passed to |
Value
A list with entries:
lsig= a vector containing the values of log(sigma) that minimize the loss function, for each quantile.err= the error bound used for each quantile. Generally each entry is identical to the argumenterr, but in some cases the function increases it to enhance stabily.ranges= the search ranges by the Brent algorithm to find log-sigma, for each quantile.store= a list, where the i-th entry is a matrix containing all the locations (1st row) at which the loss function has been evaluated and its value (2nd row), for the i-th quantile.
References
Fasiolo, M., Goude, Y., Nedellec, R. and Wood, S. N. (2017). Fast calibrated additive quantile regression. Available at https://arxiv.org/abs/1707.03307.
Examples
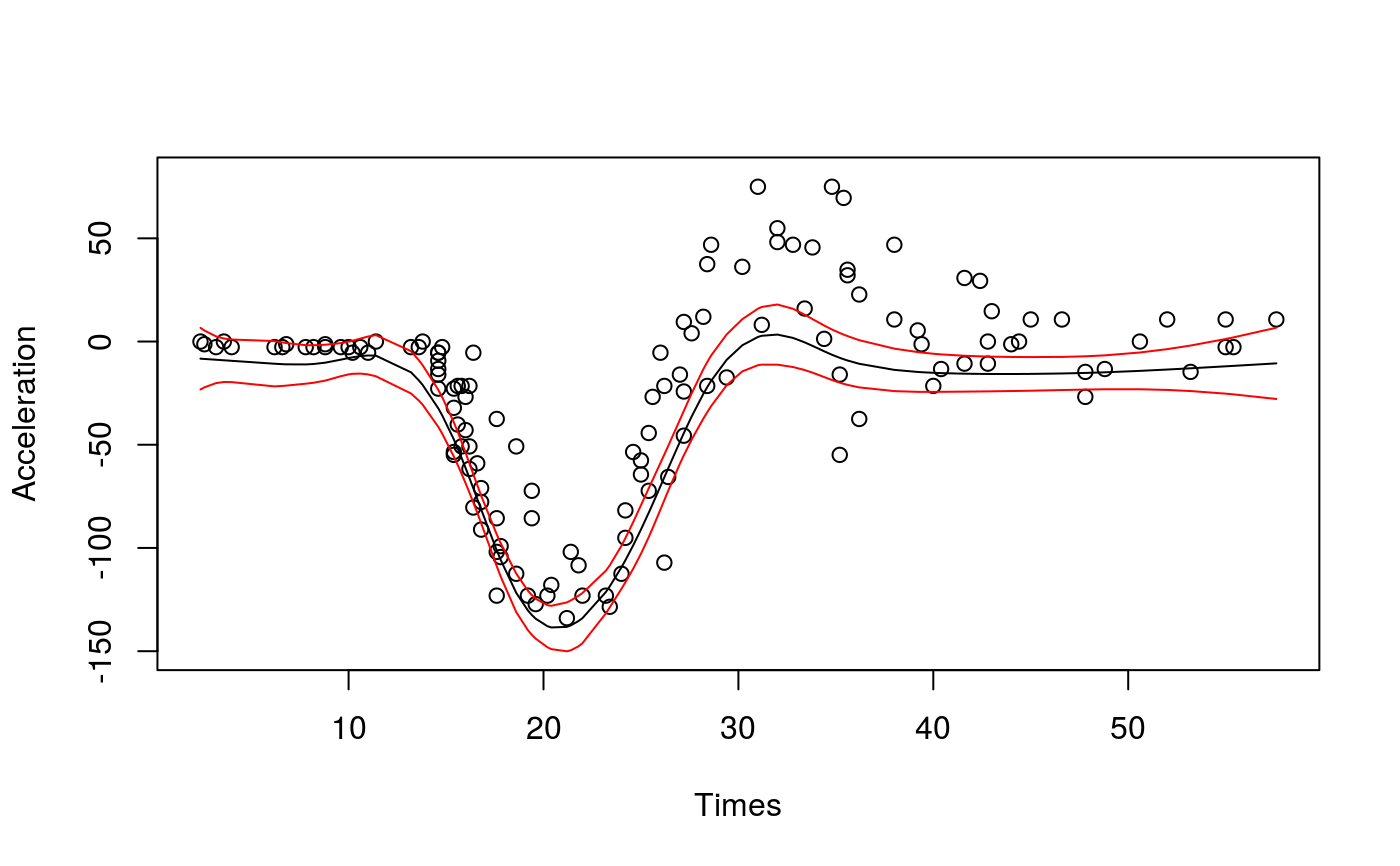
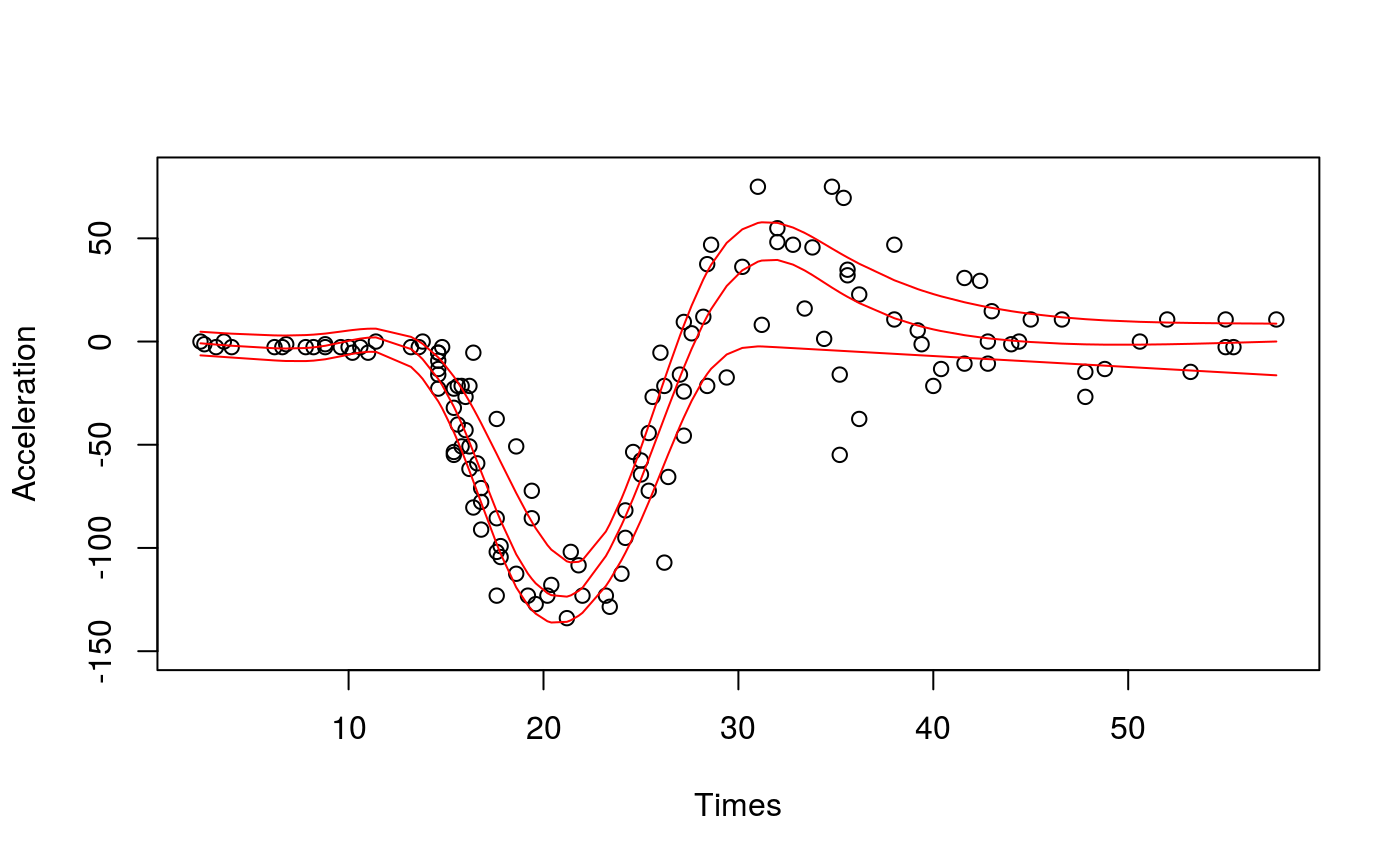
library(qgam); library(MASS) ### # Single quantile fit ### # Calibrate learning rate on a grid set.seed(5235) tun <- tuneLearnFast(form = accel~s(times,k=20,bs="ad"), data = mcycle, qu = 0.2)#> Estimating learning rate. Each dot corresponds to a loss evaluation. #> qu = 0.2...........done# Fit for quantile 0.2 using the best sigma fit <- qgam(accel~s(times, k=20, bs="ad"), data = mcycle, qu = 0.2, lsig = tun$lsig) pred <- predict(fit, se=TRUE) plot(mcycle$times, mcycle$accel, xlab = "Times", ylab = "Acceleration", ylim = c(-150, 80))### # Multiple quantile fits ### # Calibrate learning rate on a grid quSeq <- c(0.25, 0.5, 0.75) set.seed(5235) tun <- tuneLearnFast(form = accel~s(times, k=20, bs="ad"), data = mcycle, qu = quSeq)#> Estimating learning rate. Each dot corresponds to a loss evaluation. #> qu = 0.5............done #> qu = 0.25................done #> qu = 0.75.................done# Fit using estimated sigmas fit <- mqgam(accel~s(times, k=20, bs="ad"), data = mcycle, qu = quSeq, lsig = tun$lsig) # Plot fitted quantiles plot(mcycle$times, mcycle$accel, xlab = "Times", ylab = "Acceleration", ylim = c(-150, 80))# NOT RUN { # You can get a better fit by letting the learning rate change with "accel" # For instance tun <- tuneLearnFast(form = list(accel ~ s(times, k=20, bs="ad"), ~ s(times)), data = mcycle, qu = quSeq) fit <- mqgam(list(accel ~ s(times, k=20, bs="ad"), ~ s(times)), data = mcycle, qu = quSeq, lsig = tun$lsig) # Plot fitted quantiles plot(mcycle$times, mcycle$accel, xlab = "Times", ylab = "Acceleration", ylim = c(-150, 80)) for(iq in quSeq){ pred <- qdo(fit, iq, predict) lines(mcycle$times, pred, col = 2) } # }